Quand un utilisateur interroge un LLM, le moteur ne lance pas une seule recherche. Il en déclenche des dizaines en parallèle. Si vous ne monitorez pas ces sous-requêtes, vous êtes aveugle sur la majorité de votre surface de visibilité.
L’essentiel :
- Les LLM (GPT, Gemini, Perplexity) fragmentent chaque prompt en dizaines de sous-requêtes parallèles, c’est le query fan-out.
- Votre marque peut être absente de 80 % de ces sous-requêtes sans que vous le sachiez, car les outils classiques ne les trackent pas.
- Le biais linguistique aggrave le problème : 43 % des fan-outs restent en anglais même quand le prompt est dans une autre langue.
- Monitorer votre présence à l’échelle du fan-out, pas seulement du prompt initial, est le seul moyen de piloter votre visibilité LLM.
Et votre marque, ChatGPT la recommande-t-il ?
Mesurez votre présence et identifiez les marques citées à votre place. Sans carte bancaire.
Le problème : vous ne voyez qu’une fraction de votre visibilité LLM
La plupart des équipes marketing et produit qui s’intéressent à leur présence dans les réponses des LLM commettent la même erreur : elles testent quelques prompts manuellement, vérifient si leur marque apparaît dans la réponse, et en tirent des conclusions.
Le problème, c’est que cette approche ignore le mécanisme fondamental qui produit la réponse : le query fan-out.
Ce qui se passe réellement quand un utilisateur pose une question
Quand un utilisateur tape un prompt dans ChatGPT, Gemini ou Perplexity, le moteur ne cherche pas une réponse directe à cette question. Il la décompose en sous-requêtes spécialisées, les exécute en parallèle, agrège les résultats, puis synthétise une réponse unifiée.
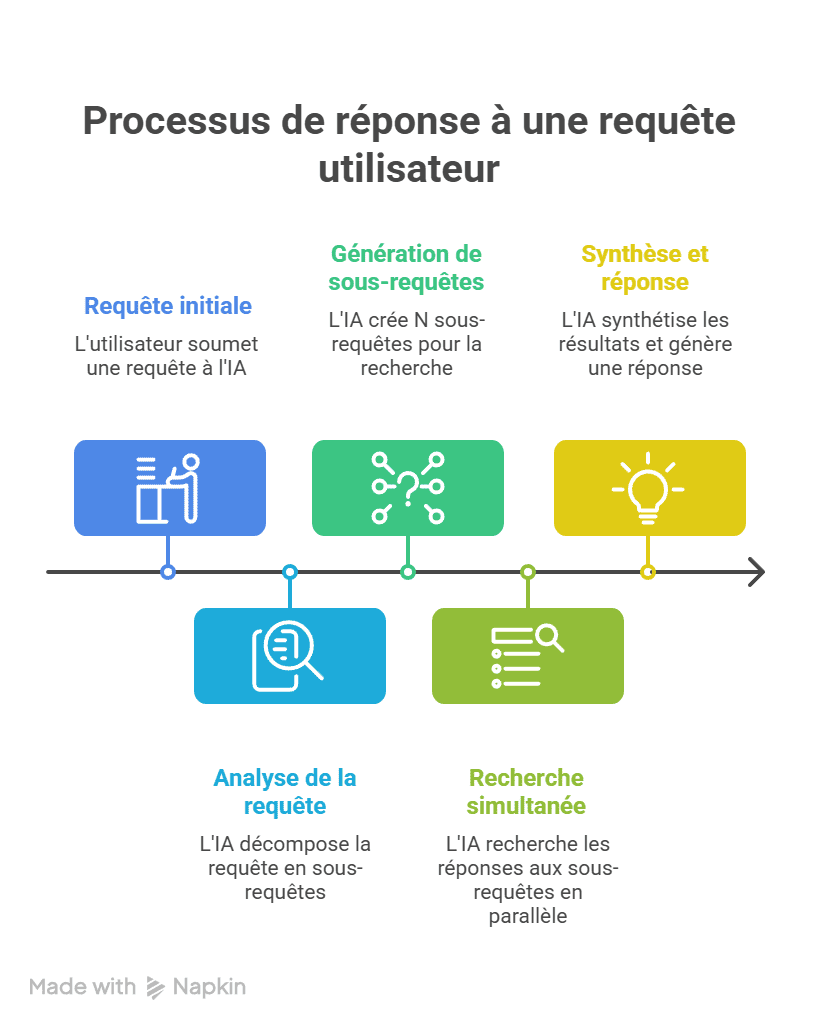
Concrètement, un prompt comme « Quel outil utiliser pour suivre ma visibilité dans les réponses IA ? » ne génère pas une recherche. Le LLM peut produire 10 à 30 sous-requêtes distinctes : définitions, comparatifs d’outils, avis utilisateurs, pricing, alternatives, cas d’usage par secteur…
Le point aveugle
Si votre outil de tracking ne teste que le prompt initial, vous mesurez votre visibilité sur 1 requête alors que le LLM en a exécuté 20 ou 30 pour construire sa réponse. Vous passez à côté de la majorité des points de contact où votre marque aurait pu apparaître, ou a été évincée.
Anatomie du fan-out : comment les LLM sélectionnent vos concurrents
Le query fan-out n’est pas un concept théorique. C’est un mécanisme documenté, notamment dans le brevet Google (synthetic queries) « Search with Stateful Chat » (US20240289407A1, août 2024), et observé empiriquement à travers plusieurs études récentes.
Pour une équipe produit ou marketing, l’important n’est pas le fonctionnement technique du fan-out, c’est de comprendre où se joue la sélection.
Chaque sous-requête est un terrain de compétition distinct
Prenons un exemple dans notre domaine. Un utilisateur demande : « Quel est le meilleur outil de monitoring de visibilité IA ? »
Le LLM va potentiellement générer des sous-requêtes couvrant :
| Type de sous-requête | Exemple généré | Ce qui se joue |
|---|---|---|
| Listing | « AI visibility monitoring tools 2026 » | Être dans la liste initiale |
| Comparatif | « Cockpyt AI vs Qwairy vs Peec AI » | Positionnement concurrentiel |
| Pricing | « AI brand monitoring tool pricing » | Apparaître dans l’évaluation coût |
| Avis | « Cockpyt AI review » | Signaux de confiance |
| Use case | « LLM visibility tracking for SaaS » | Pertinence sectorielle |
| Alternative | « Otterly alternative for LLM tracking » | Captation de flux concurrent |
Si votre marque n’est présente que sur 2 de ces 6 facettes, le LLM n’a pas assez de signaux pour vous inclure dans sa réponse finale. La synthèse privilégie les entités qui apparaissent de manière récurrente à travers les résultats des sous-requêtes.
Implication produit
Monitorer sa présence LLM à l’échelle du prompt est insuffisant. Il faut tracker la visibilité par facette de fan-out : listing, comparatif, pricing, avis, use case, alternative. C’est ce que permet un tracking structuré par type de requête.
Le biais linguistique : un filtre invisible qui exclut les marques non anglophones

Le fan-out ne se contente pas de fragmenter les requêtes : il les traduit. Et c’est là que le problème devient structurel pour toute marque opérant hors du marché anglophone.
- 43% des fan-outs de ChatGPT pour des prompts non anglophones sont formulés en anglais
- 78% des sessions non anglophones incluent au moins une sous-requête en anglais
- 60%+ de sessions avec fan-out anglophone, quel que soit le marché non anglophone
Source : étude Peec AI, février 2026, plus de 10 millions de prompts analysés, environ 20 millions de fan-out queries.
Ce que ça signifie pour votre tracking
Si vous ne monitorez que des prompts dans la langue de votre marché, vous ignorez près de la moitié des sous-requêtes réellement exécutées par le LLM. Votre dashboard de visibilité affiche un score qui ne reflète pas la réalité du parcours de décision de l’IA.
Conséquence directe
Une marque française leader sur son marché peut être totalement absente des fan-outs anglophones, et donc de la réponse finale, sans que son outil de monitoring ne détecte le problème. Le tracking doit couvrir les deux langues pour refléter le comportement réel du LLM.
GPT-5.3 vs GPT-5.4 : le nombre de sous-requêtes vient d’être multiplié par 8
Le query fan-out n’est pas une constante. Sa volumétrie dépend du modèle qui répond, et elle vient de bouger violemment. En une version, OpenAI a fait passer le nombre moyen de sous-requêtes de ~1 à 8,5 par prompt. Votre surface de compétition dans ChatGPT a été multipliée par huit sans que vous touchiez à quoi que ce soit.
~1 sous-requête sur GPT-5.3, 8,5 sur GPT-5.4
| Critère | GPT-5.3 | GPT-5.4 |
|---|---|---|
| Sous-requêtes par prompt (moyenne) | ~1 | ~8,5 |
| Stratégie de recherche | requête large, « qu’est-ce qui existe ? » | décomposition ciblée + opérateurs site: sur domaines de marque et plateformes d’avis |
| Citations vers les sites de marque (first-party) | ~8 % | ~56 % |
| Recoupement des sources citées entre les deux modèles | ~7 % | ~7 % |
Le chiffre à retenir n’est pas seulement le 8,5. C’est le **7 % de recoupement** : GPT-5.3 et GPT-5.4 citent des sources quasi totalement différentes. Une marque optimisée pour l’un peut être invisible sur l’autre.
Ce que GPT-5.4 change concrètement
GPT-5.4 ne cherche pas seulement « plus ». Il cherche différemment. Sur 50 prompts, il a envoyé 156 requêtes avec opérateur `site:` — aucun autre modèle n’en a utilisé un seul. Il interroge directement les pages de marque (pricing, fonctionnalités, docs) et les plateformes de validation : G2, Capterra, comparateurs, sites d’avis.
Trois conséquences directes :
- Il pré-sélectionne les marques à investiguer à partir de ses données d’entraînement, avant même de lancer une requête. Si votre marque n’est pas dans cet ensemble de considération, aucun effort SEO ne la fera entrer.
- Vos propres pages sont interrogées en direct. Vos pages pricing, fonctionnalités et docs doivent être crawlables, structurées et à jour : elles sont lues comme des sources primaires.
- Votre présence sur les plateformes tierces pèse bien plus lourd. G2 et Capterra figurent parmi les cibles `site:` les plus fréquentes. Un profil faible sur ces plateformes = un angle mort sur 5.4.
Implication GEO
Passer de 1 à 8,5 sous-requêtes ne dilue pas la compétition, il la démultiplie. Et avec 56 % des citations dirigées vers les sites de marque, le travail on-site (pages produit propres, données structurées, pricing transparent) redevient un levier de visibilité IA de premier ordre, pas seulement un sujet SEO.
Le paradoxe : plus de fan-outs, moins de visibilité sur les données
GPT-5.3 a fait deux choses simultanément : réduire le fan-out à ~1 requête et casser les méthodes d’extraction grand public. Le champ `search_model_queries` n’apparaît plus dans le JSON lu via l’onglet Network des DevTools, et la plupart des extensions qui le scrapaient renvoient une colonne vide sur 5.3+. GPT-5.4 a inversé la volumétrie (8,5 requêtes) sans rétablir cette visibilité côté interface.
Nuance importante : la donnée n’a pas totalement disparu. L’endpoint authentifié `/backend-api/conversation/` (via un script console exécuté dans votre propre session) renvoie toujours les `search_model_queries`, y compris sur les modèles récents – c’est ainsi que Writesonic continue d’extraire les fan-outs en 2026. Ce qui a cassé, ce sont les méthodes « lecture passive » (DevTools Network, extensions frontend).
Conséquence directe
Pour du diagnostic ponctuel, le script console sur votre propre session fonctionne encore. Pour du monitoring systématique et multi-modèles, l’API Responses (avec `web_search`) reste la seule source fiable à l’échelle, avec une limite à connaître : les system prompts de l’API et de l’interface web diffèrent, donc les fan-outs de l’API sont une approximation de ce que voient les utilisateurs réels, pas une copie exacte. Dans tous les cas, une stratégie de monitoring construite sur le scraping frontend est condamnée à casser à la prochaine mise à jour, et la cadence s’accélère : GPT-5.5 est déjà arrivé.
Comment récupérer les query fan-out de ChatGPT : le workflow concret (avril 2026)
Avant de monitorer quoi que ce soit, encore faut-il voir les sous-requêtes que ChatGPT génère réellement. Par défaut, l’interface n’affiche que les sources citées, pas les recherches effectuées en coulisses.
Point important : les méthodes d’extraction ont évolué rapidement. Ce qui fonctionnait fin 2025 ne fonctionne plus forcément aujourd’hui. Depuis le déploiement de GPT-5.3 comme modèle par défaut, OpenAI a supprimé les données de fan-out du JSON de conversation accessible via le navigateur. Les extensions et outils qui scrapaient ces données en frontend ont été impactés. Voici l’état des lieux à date, et ce qui fonctionne encore.
Méthode 1 : les DevTools du navigateur, fonctionne, mais plus sur le modèle par défaut
Pendant plus d’un an, la méthode standard consistait à ouvrir les Chrome DevTools, filtrer les requêtes réseau, et lire les fan-outs directement dans le JSON de conversation. Depuis GPT-5.3, le champ search_model_queries a disparu du payload visible dans le navigateur pour ce modèle.
La méthode reste fonctionnelle si vous sélectionnez manuellement un modèle compatible (GPT-4o, o3, o4-mini) avant de lancer votre prompt. Voici la procédure :
- Choisissez le bon modèle. Dans ChatGPT, cliquez sur le sélecteur de modèle et passez sur GPT-4o ou o3. Si vous restez sur le modèle par défaut (GPT-5.3+), les fan-outs ne seront pas visibles dans le JSON.
- Posez un prompt qui déclenche la recherche web. Exemples : « Quels sont les meilleurs outils de monitoring de visibilité IA en 2026 ? », « Comparatif Cockpyt AI vs Qwairy ». Les questions de culture générale ne déclenchent pas de fan-out. Les déclencheurs les plus fiables sont les termes « best », « top », « review », « vs », « 2026 », « comparison », « free » et les requêtes à intention locale.
- Attendez que la réponse complète se charge, sources et citations incluses. Si ChatGPT ne montre pas de sources, il a répondu depuis ses données d’entraînement, pas de fan-out à récupérer.
- Copiez l’identifiant de conversation dans la barre d’URL. C’est la séquence alphanumérique après
/c/, par exemple68f1007d. - Ouvrez les DevTools : clic droit n’importe où sur la page → Inspecter (ou
Ctrl+Shift+Isur Windows,Cmd+Option+Isur Mac). - Allez dans l’onglet Network. Attention : les DevTools doivent être ouverts avant de rafraîchir la page, sinon les requêtes réseau ne seront pas capturées.
- Rafraîchissez la page (
Ctrl+R). Des dizaines de requêtes vont apparaître dans la liste. - Filtrez par votre identifiant de conversation : collez-le dans la barre de filtre du Network tab. Vous cherchez une requête de type
fetchouxhr. - Cliquez sur la requête filtrée, puis ouvrez l’onglet Response (pas Headers, pas Preview, Response).
- Faites
Ctrl+Fet cherchezsearch_model_queries. Si la recherche web a été déclenchée, vous verrez les requêtes exactes envoyées par ChatGPT à Bing, en clair.
Si vous ne trouvez pas search_model_queries
- vous êtes sur GPT-5.3 ou plus récent, OpenAI a retiré ce champ du JSON pour ces modèles. Repassez sur GPT-4o ou o3.
- ChatGPT n’a pas déclenché de recherche web, essayez un prompt plus transactionnel avec un marqueur temporel (« meilleur X en 2026 »).
- Les DevTools n’étaient pas ouverts avant le rafraîchissement, les requêtes réseau n’ont pas été capturées. Rouvrez et re-rafraîchissez.
Méthode 2 : les extensions Chrome spécialisées, vérifiez la compatibilité modèle
Plusieurs extensions Chrome automatisent l’extraction des fan-out queries directement dans l’interface ChatGPT. Elles interceptent les requêtes réseau et les affichent en overlay. Mais depuis le changement de format de GPT-5.3, toutes ne sont pas à jour. Avant d’installer une extension, vérifiez dans son changelog si elle supporte les modèles récents.
| Extension | Ce qu’elle fait | Compatibilité avril 2026 |
|---|---|---|
| Keyword Surfer (Surfer SEO) | Affiche les fan-out queries + volume de recherche associé | Supporte o3, o4, o4-mini. Gratuit. |
| Keywords Everywhere | Widget fan-out intégré avec volume de recherche | Plan gratuit et payant. Volume sur les fan-outs. |
| ChatGPT Search & Fan-outs Capture (RESONEO) | Capture fan-outs, citations, carousels produits, entités, mentions de marque | Mis à jour post-GPT-5. Export TSV, dashboard analytics, détection des types de fan-outs (Search, Shopping, Images). |
| AI Search Fan-out Tracker | Capture automatique des requêtes + export CSV | Mis à jour pour o3 et GPT-5. Supporte aussi Gemini. |
| LLMrefs Query Extractor | Extraction des requêtes + sources en un clic | Affiche aussi les URLs crawlées par ChatGPT. |
Ces extensions résolvent le problème de l’effort manuel, mais partagent deux limites : elles ne capturent que les fan-outs de vos propres conversations, et leur fonctionnement dépend de la structure du payload côté OpenAI, qui peut changer à tout moment, comme GPT-5.3 l’a démontré.
Méthode 3 : l’API OpenAI, la seule méthode fiable à l’échelle en mars 2026
Depuis que les données de fan-out ont disparu de l’interface web pour GPT-5.3+, l’API Responses d’OpenAI reste le canal le plus fiable pour récupérer les sous-requêtes. Les fan-outs y sont toujours accessibles, même sur les modèles les plus récents.
Le principe : vous envoyez un prompt via l’API avec le paramètre web_search activé, et vous récupérez les sous-requêtes générées, les sources crawlées et la réponse complète en JSON structuré. Le script Python peut être exécuté en batch sur des centaines de prompts.
C’est la seule approche qui permet de :
- Extraire les fan-outs sur tous les modèles, y compris GPT-5.3+ où les DevTools ne fonctionnent plus
- Tester des centaines de prompts par batch
- Comparer les fan-outs entre modèles (GPT-4o, o3, o4, GPT-5.x), les études montrent que GPT-5.4 génère en moyenne 8,5 fan-outs par prompt, contre environ 1 pour GPT-5.3
- Mesurer la stabilité des sous-requêtes dans le temps
- Détecter les fan-outs anglophones générés sur des prompts francophones
C’est ce que nous faisons dans notre outil Cockpyt AI.
Quelle méthode choisir ?
| Besoin | Méthode recommandée | Coût |
|---|---|---|
| Diagnostic rapide sur 5-10 prompts | Extension Chrome (sur modèle compatible) ou DevTools sur GPT-4o/o3 | Gratuit |
| Veille régulière sur vos requêtes clés | Extension Chrome mise à jour (Keyword Surfer, RESONEO, AI Search Fan-out Tracker) | Gratuit à freemium |
| Analyse systématique à l’échelle, tous modèles | API OpenAI (Responses + web_search) chez Cockpyt AI | Payant |
L’accès aux fan-outs se referme
La tendance est claire : OpenAI réduit progressivement la visibilité des sous-requêtes dans l’interface web. Ce qui était accessible gratuitement via les DevTools en 2025 nécessite désormais soit un modèle spécifique, soit un accès API. Les outils GEO qui reposaient uniquement sur le scraping frontend doivent migrer vers des sources de données API. Si vous construisez une stratégie de monitoring, partez directement sur une approche API-first, c’est la seule qui ne risque pas de casser à la prochaine mise à jour d’OpenAI.
L’important n’est pas la méthode choisie, c’est de passer du mode « je teste un prompt à la main » au mode « je comprends comment le LLM décompose les requêtes de mon marché ». Sans cette visibilité sur les sous-requêtes réelles, toute stratégie de contenu GEO repose sur des hypothèses.
Ce qu’il faut réellement mesurer : les KPIs du fan-out
Le passage du SEO classique au monitoring de visibilité LLM impose de nouveaux indicateurs. Les métriques habituelles (position, CTR, impressions) ne captent pas le mécanisme du fan-out. Voici les KPIs qui comptent quand on veut piloter sa présence dans les réponses génératives.
| KPI | Ce qu’il révèle | Pourquoi le fan-out change la donne |
|---|---|---|
| Taux de mention par facette | Sur combien de types de sous-requêtes votre marque apparaît | Une présence sur 2/6 facettes = signal faible pour le LLM |
| Share of Voice LLM | Part de vos mentions vs concurrents dans les réponses | Le fan-out multiplie les opportunités de citation concurrentielle |
| Couverture linguistique | Présence dans les fan-outs anglophones vs langue locale | 43% de la surface de visibilité est en anglais par défaut |
| Sentiment par facette | Tonalité associée à votre marque dans chaque type de sous-requête | Un sentiment négatif sur la facette « avis » impacte la synthèse globale |
| Rang dans la synthèse | Position de votre marque dans l’ordre de la réponse finale | Le Reciprocal Rank Fusion agrège les positions sur toutes les sous-requêtes |
Trois actions immédiates pour reprendre le contrôle
Comprendre le fan-out est une chose. Agir en est une autre. Voici les trois leviers qui ont un impact direct sur votre visibilité dans les réponses LLM, côté contenu, pas côté code.
1. Cartographiez vos facettes manquantes
Listez les types de sous-requêtes que le LLM génère sur votre thématique (listing, comparatif, pricing, avis, use case, alternative, intégrations). Pour chaque facette, vérifiez si du contenu indexable existe sur votre domaine ou sur des sites tiers qui vous mentionnent. Les facettes sans couverture sont vos angles morts.
2. Doublez votre surface avec du contenu anglophone
Les données sont sans ambiguïté : près de la moitié des fan-outs sont en anglais, quel que soit le marché. Les pages stratégiques, page produit, comparatifs, landing pages verticales, doivent exister en version anglaise. Ce n’est pas une question de SEO international, c’est une question de visibilité dans le mécanisme même du fan-out.
3. Monitorez par facette, pas par prompt
Un dashboard qui teste 50 prompts et compte les mentions ne suffit plus. Le monitoring doit décomposer les résultats par type de sous-requête pour identifier précisément où votre marque gagne et où elle est absente. C’est la seule façon de prioriser les actions de contenu avec un ROI mesurable.
Votre marque est-elle visible dans les fan-outs ?
Cockpyt AI track vos mentions et citations dans les réponses de GPT, Gemini, Claude et Perplexity, par facette, par langue, par concurrent.
Questions fréquentes
Quelle différence entre le query fan-out et la query expansion classique ?
La query expansion enrichit une requête avec des synonymes ou des corrections. Le fan-out est un processus en plusieurs étapes : le LLM décompose la requête en sous-requêtes autonomes, les exécute sur des sources multiples en parallèle, puis fusionne les résultats. C’est un pipeline de synthèse, pas un simple élargissement lexical.
Tous les LLM utilisent-ils le query fan-out ?
Les moteurs avec une fonctionnalité de recherche intégrée (ChatGPT Search, Gemini, Perplexity) utilisent tous une forme de décomposition de requêtes. L’intensité du fan-out varie selon le type de prompt : les requêtes évaluatives et comparatives (« best », « top », « vs ») génèrent significativement plus de sous-requêtes que les questions factuelles simples.
Peut-on voir les sous-requêtes générées par un LLM ?
Perplexity affiche parfois les recherches effectuées dans son interface. Pour ChatGPT et Gemini, les sous-requêtes ne sont pas visibles par l’utilisateur final. L’analyse à grande échelle (comme celle de Peec AI sur 20 millions de fan-out queries) nécessite des méthodologies spécifiques d’observation du trafic et des logs.
Est-ce que le fan-out rend le SEO classique obsolète ?
Non. Les requêtes factuelles simples déclenchent peu de fan-out, et le SEO classique reste le canal dominant pour ce type de recherche. Le fan-out impacte surtout les requêtes à fort enjeu décisionnel, précisément celles qui génèrent le plus de valeur commerciale. Les deux approches sont complémentaires.
Pourquoi les fan-outs anglophones impactent-ils les marques francophones ?
Parce que les LLM traduisent silencieusement une partie des sous-requêtes en anglais, même quand l’utilisateur écrit en français. Le corpus anglophone étant plus large, l’IA y trouve davantage de résultats, et les marques qui n’ont pas de présence web en anglais sont exclues de ces sous-requêtes avant même l’étape de ranking.