Ce qu’il faut retenir :
- ChatGPT ne rend pas deux fois la même réponse. Tester un prompt une seule fois, c’est mesurer du bruit.
- Cinq niveaux de mesure cohabitent : présence, position, Share of Voice, fréquence pondérée par intention, contexte. Confondre les niveaux fausse la conclusion.
- Une mesure exploitable repose sur un panier de 20 à 50 prompts, répétés 3 à 5 fois, suivis dans la durée.
- Un KPI qui ne déclenche aucune action est une métrique de vanité. Arrêtez de la suivre.
Et votre marque, ChatGPT la recommande-t-il ?
Mesurez votre présence et identifiez les marques citées à votre place. Sans carte bancaire.
ChatGPT n’est pas déterministe : votre mesure est-elle fiable ?
Votre mesure n’est pas fiable si elle repose sur un seul test par prompt. ChatGPT génère ses réponses de manière probabiliste, pas déterministe. Le même prompt, soumis deux fois à quelques minutes d’écart, peut citer des marques différentes, dans un ordre différent, avec des sources différentes.
La cause technique est documentée. OpenAI expose un paramètre temperature qui contrôle l’aléatoire de la génération. Au-dessus de zéro, deux exécutions du même prompt produisent des sorties qui divergent. Et la température par défaut de l’interface ChatGPT n’est pas zéro.
Plusieurs sources de variance s’ajoutent à cette base. La version du modèle change la sélection des marques citées. Selon l’étude RESONEO sur les variantes ChatGPT 5.3 Instant et 5.4 Thinking (2026), un même prompt peut perdre jusqu’à 20 % de ses domaines uniques d’une variante à l’autre. La mémoire du compte ChatGPT, quand elle est active, oriente les recommandations. Le moment du test influe sur les résultats du web search. La localisation aussi.
Conséquence directe pour votre mesure. Si vous testez un prompt à un instant T, sur un seul compte, dans une seule version, vous capturez un échantillon de 1 dans un espace de variations large. Vous mesurez du bruit, et vous prenez des décisions sur du bruit.
Une mesure fiable demande trois conditions, qu’on détaille plus loin : un panier de prompts représentatif, plusieurs répétitions par prompt, et un suivi dans le temps. Sans ces trois conditions, vos chiffres bougent sans que vous puissiez dire si quelque chose a changé pour votre marque.
Pourquoi mesurer un seul prompt, une seule fois est une erreur :
- ChatGPT génère ses réponses de manière probabiliste, pas déterministe.
- Le paramètre interne temperature > 0 introduit de l’aléatoire : deux exécutions du même prompt produisent des sorties différentes.
- Les versions de modèles (ex. 5.3 Instant vs 5.4 Thinking) modifient les marques citées et peuvent faire perdre jusqu’à 20 % des domaines uniques d’une variante à l’autre.
- La mémoire du compte influence les recommandations et ajoute une couche de variance.
- Le moment du test change les résultats du web search (index, fraîcheur, disponibilité).
- La localisation modifie les réponses, les sources et les marques mises en avant.
- Un test unique = un **échantillon isolé** dans un espace de variations très large.
Les 5 niveaux de mesure de votre visibilité ChatGPT
Cinq métriques décrivent votre visibilité ChatGPT, et chacune répond à une question différente. Les confondre, c’est tirer la mauvaise conclusion.
La présence : êtes-vous cité, oui ou non ?
La présence est une métrique binaire. Sur un prompt donné, votre marque est citée, ou elle ne l’est pas. C’est le point de départ, et c’est insuffisant. Un taux de présence de 60 % sur votre panier ne dit rien de votre poids dans la réponse, ni de la qualité du contexte. Mais s’il est à 0 %, vous savez que vous n’avez pas de problème de mesure : vous avez un problème de visibilité.
La position : où apparaissez-vous dans la réponse ?
La position mesure l’ordre de votre marque dans la liste des marques citées. Être cité en premier ou en cinquième change tout. ChatGPT met en avant les premières citations, et la lecture humaine s’arrête vite. La position s’exprime en moyenne sur les tests où vous êtes cité, et n’a aucun sens si la présence est à zéro.
Le Share of Voice : quel est votre poids face aux concurrents ?
Le Share of Voice mesure votre part dans le volume total des citations de votre secteur. Sur 100 citations de marques pour vos prompts cibles, combien vous reviennent ? C’est la métrique de benchmark concurrentiel, et c’est la plus parlante face à une direction. Elle exige que vous mesuriez vos concurrents en même temps que vous, sur le même panier.
La fréquence pondérée par intention : tous les prompts ne valent pas le même volume
Être cité 100 fois sur des prompts informationnels génériques ne pèse pas autant que d’être cité 10 fois sur des prompts à forte intention commerciale. La fréquence pondérée par intention applique un coefficient au volume de citations selon le potentiel business de chaque prompt. Sans pondération, vos chiffres mélangent du trafic qualifié et du bruit.
Le contexte : dans quelles conditions êtes-vous cité ?
Le contexte regarde ce qui entoure votre citation. Êtes-vous cité comme référence, comme exemple, comme contre-exemple ? Avec un sentiment positif ou négatif ? Sur quel angle de la requête ? Cette métrique est qualitative, plus lourde à automatiser, et celle qui révèle les hallucinations IA sur votre marque.
| Niveau | Question à laquelle elle répond | Erreur typique |
|---|---|---|
| Présence | Suis-je cité, oui ou non ? | S’en contenter et négliger la position |
| Position | Où dans la réponse ? | Calculer la moyenne sur les tests sans présence |
| Share of Voice | Quel est mon poids face aux concurrents ? | Comparer sans panier commun de prompts |
| Fréquence pondérée par intention | Quels prompts génèrent vraiment du business ? | Compter toutes les citations à poids égal |
| Contexte | Comment suis-je cité ? | L’ignorer et passer à côté des hallucinations |
Comment construire un panier de prompts qui ne ment pas
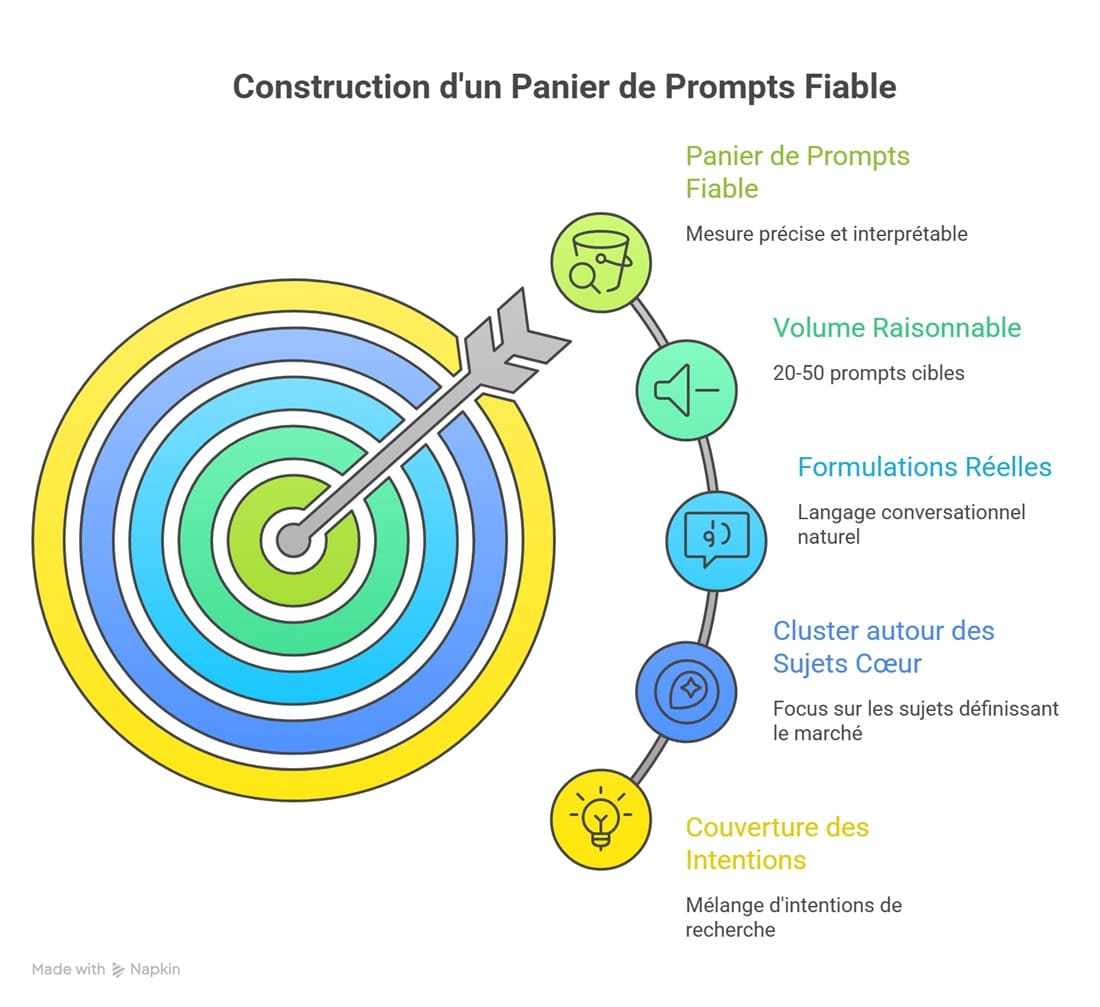
Un panier de prompts fiable repose sur la représentativité, pas sur le volume. Un panier de 500 prompts génériques mesure moins bien qu’un panier de 30 prompts choisis pour leur valeur business et leur diversité d’intention.
Ce que nous faisons chez Cockpyt AI :
- Couverture des intentions. Mélangez prompts notoriété, comparatifs, intentionnels, de douleur et budgétaires. Un panier qui ne couvre qu’une intention vous donne une vue tronquée.
- Cluster autour de vos sujets cœur. Concentrez les prompts sur trois à cinq clusters thématiques, ceux qui définissent votre marché. Couvrir vingt sujets en surface ne sert à rien.
- Formulations réelles. Les utilisateurs n’écrivent pas en mots-clés. Reprenez la formulation conversationnelle exacte, longue, naturelle, telle qu’elle apparaît dans ChatGPT.
- Volume raisonnable. 20 à 50 prompts cibles suffisent pour un secteur. Au-delà, la charge de mesure et de maintenance devient un frein.
Un panier mal construit produit des chiffres qui bougent sans raison interprétable. Un panier bien construit produit une mesure qui se compare dans le temps. La différence ne se voit pas tout de suite, mais elle se paie au bout de trois mois de suivi.
Combien de tests faut-il pour mesurer juste ?
Une mesure exploitable demande au minimum 3 à 5 répétitions par prompt, sur un rythme hebdomadaire ou bi-hebdomadaire. C’est le seuil en-dessous duquel le bruit l’emporte sur le signal.
La logique tient en trois temps.
- Plusieurs exécutions par prompt. Trois à cinq exécutions du même prompt, à intervalles courts, vous donnent une distribution de citations. Vous pouvez alors raisonner sur une moyenne plutôt que sur un point.
- Plusieurs prompts par cluster. Le panier de 20 à 50 prompts évoqué plus haut produit une mesure agrégée par cluster, plus stable qu’un prompt isolé.
- Plusieurs cycles dans le temps. La donnée d’un instantané n’a pas de sens. Ce qui compte, c’est la tendance sur quatre à six semaines glissantes, mise en regard des actions que vous avez menées.
L’exercice est lourd à la main. 30 prompts × 5 exécutions × suivi hebdomadaire, c’est 150 tests par semaine, sans compter le scrapping des marques citées et la consolidation. Pour un cluster unique. Et il faut y ajouter le suivi de vos concurrents sur le même panier pour calculer un Share of Voice.
D’où l’usage d’outils dédiés ou de scripts maison pour automatiser. On y revient plus loin.
Métrique d’action ou métrique de vanité : la règle des « lundi matin »
Un KPI a de la valeur quand sa variation déclenche une décision. Sinon, c’est une métrique de vanité. La règle tient en une question : si ce chiffre baisse de 20 % la semaine prochaine, qu’est-ce que vous faites lundi matin ?
Pas de réponse claire, arrêtez de suivre la métrique. Trois exemples concrets.
- Métrique de vanité : « Notre marque est citée 847 fois ce mois-ci par ChatGPT. » Sans répartition par cluster, sans pondération par intention, ce chiffre ne déclenche aucune action. Il décore un slide.
- Métrique d’action : « Notre Share of Voice sur le cluster comparatif est passé de 18 % à 12 % en quatre semaines, et le concurrent X a gagné 7 points sur la même période. » Action lundi : auditer ce qui a changé côté concurrent, identifier les prompts perdus, prioriser les pages à actualiser.
- Métrique d’action : « Sur 6 tests d’un prompt commercial cible, ma marque a été citée 1 fois sur 6. » Action lundi : prompt isolé, vérifier la couverture éditoriale du sujet et la présence sur les sources que ChatGPT mobilise pour ce cluster.
Le filtre est sévère, et c’est voulu. Mieux vaut suivre trois métriques qui pilotent des décisions que quinze qui produisent des rapports. Ce framing est repris d’Hi-commerce (2026).
Mesurer en pratique : test manuel, scripts, ou plateforme dédiée ?
Vous avez trois options pour passer à la mesure, avec des coûts et des limites différents.
Le test manuel. Vous ouvrez ChatGPT, vous tapez votre prompt, vous notez les marques citées dans un tableau. Coût : zéro, hors temps. Limite : impraticable au-delà de 10 prompts, impossible à maintenir dans la durée, et le test manuel se fait souvent sur un seul compte, donc avec une mémoire qui biaise la mesure. Utile pour un audit ponctuel, pas pour un suivi.
Les scripts maison. Vous interrogez l’API OpenAI en boucle, vous parsez les marques citées, vous stockez. Coût : du temps de développement et un budget API. Limite : vous mesurez l’API, qui ne se comporte pas exactement comme l’interface ChatGPT que vos utilisateurs réels emploient. Vous perdez aussi la dimension web search activée par défaut côté grand public.
La plateforme dédiée. Un outil GEO automatise les répétitions, gère le panier, calcule les cinq métriques, suit vos concurrents et la tendance dans le temps. Coût : un abonnement mensuel. Bénéfice : la mesure tient sans charge récurrente, et vous ré-investissez le temps gagné dans les actions.
Nous avons concu Cockpyt AI pour la troisième option. L’outil mesure vos citations ChatGPT, votre position, votre Share of Voice et vos concurrents, sur un panier de prompts que vous définissez, sans test manuel. Et il fait la même chose sur Perplexity, Gemini et Claude, ce qui est l’autre angle mort de la mesure manuelle.
FAQ
Combien de prompts faut-il dans un panier de mesure ChatGPT ?
20 à 50 prompts cibles suffisent pour un secteur. Au-delà, la charge de maintenance devient un frein. En-dessous de 15, vous perdez la couverture des intentions. La règle est : couvrir trois à cinq clusters thématiques, avec un mélange équilibré d’intentions de recherche.
Pourquoi mes mesures ChatGPT varient-elles d’une semaine sur l’autre ?
Parce que ChatGPT n’est pas déterministe par défaut. La même question peut produire des réponses différentes selon le moment, la version du modèle, la mémoire du compte, et le résultat du web search. La variance est une caractéristique du moteur, pas une erreur de votre méthode. Vous la réduisez avec des répétitions et un suivi dans le temps.
Faut-il mesurer sur l’interface ChatGPT ou sur l’API ?
L’interface reflète ce que vivent vos utilisateurs réels, y compris le web search et la mémoire. L’API donne une mesure plus stable mais plus éloignée du comportement utilisateur. La bonne mesure utilise l’interface, ou un outil qui la simule fidèlement. L’API seule sous-estime souvent la réalité.
Quelle différence entre Share of Voice et taux de mention ?
Le taux de mention mesure votre présence sur le panier, indépendamment des concurrents. Le Share of Voice mesure votre part dans le volume total de citations de votre secteur. Le premier répond à « suis-je visible ». Le second répond à « combien de place je prends face aux autres ».
À quelle fréquence faut-il mesurer ?
Une fréquence hebdomadaire ou bi-hebdomadaire suffit pour la plupart des secteurs. Plus rapide n’apporte rien parce que les évolutions de visibilité ChatGPT ne se jouent pas à la journée. Plus lent fait passer à côté des décrochages provoqués par des changements de version du modèle.
Peut-on mesurer la visibilité ChatGPT sans outil dédié ?
Oui, sur un cluster réduit et pour un audit ponctuel. Le test manuel ou le script maison fonctionnent. La limite arrive vite : suivi dans le temps, plusieurs concurrents, plusieurs clusters, plusieurs moteurs. À ce stade, un outil dédié devient plus rentable que le temps qu’il fait gagner.
Sources
OpenAI, documentation du paramètre temperature dans l’API, platform.openai.com, consultée en mai 2026.
Hi-commerce, « Mesurer sa visibilité dans ChatGPT, Perplexity et Gemini : le guide 2026 », hi-commerce.fr, 2026.